ニュースフィード(バックエンド)
要件の明確化
面接のはじめ少なくとも以下の要件を確認してから設計にはいりましょう
コア機能
- ニュースフィードの閲覧;ユーザーは画像、テキスト、タイムスタンプを含むニュース記事のリストを見ることができます。
- 時系列順で閲覧できる
- フォローしているカテゴリーの記事を優先的に表示する
- フィードの更新: 定期的にニュース記事を更新し、最新の情報をユーザーに提供します。
- 管理者は新しいニュース記事を作成できる
その他
- 画像ありかどうか
非機能要件
面接官によってこれは話さなくても良いというケースもあるがどこまで話す必要があるのか擦り合わせると良いです
- 1日あたり10,000新記事
- ニュースフィードの閲覧は500ms以内に応答する
- 新しい記事がフィードに出てくるまでの遅延
- システムは大規模なユーザー数(1億)を扱える
ハイレベル設計
API設計
ニュース記事の作成 (管理者向け)
POST /admin/news
Request:
{
"title": string,
"content": string,
"category": []string,
"publishedAt": timestamp,
}
Response:
{
"id": string,
"success": boolean,
"message": string
}
カテゴリーのフォロー/アンフォロー (ユーザー向け)
POST /user/categories/:categoryId/follow
POST /user/categories/:categoryId/unfollow
Response:
{}
ニュースフィードを取得: ユーザーのニュースフィードを取得します。ページ番号とサイズのパラメータを受け取り、ページングを行います。
GET /feed
Response:
{
"articles": [
{
"id": string,
"title": string,
"summary": string,
"publishedAt": timestamp,
"category": []string
}
]
}
大量のデータを読み込むと遅延が発生するため、ページングが必要です。
データの流れ
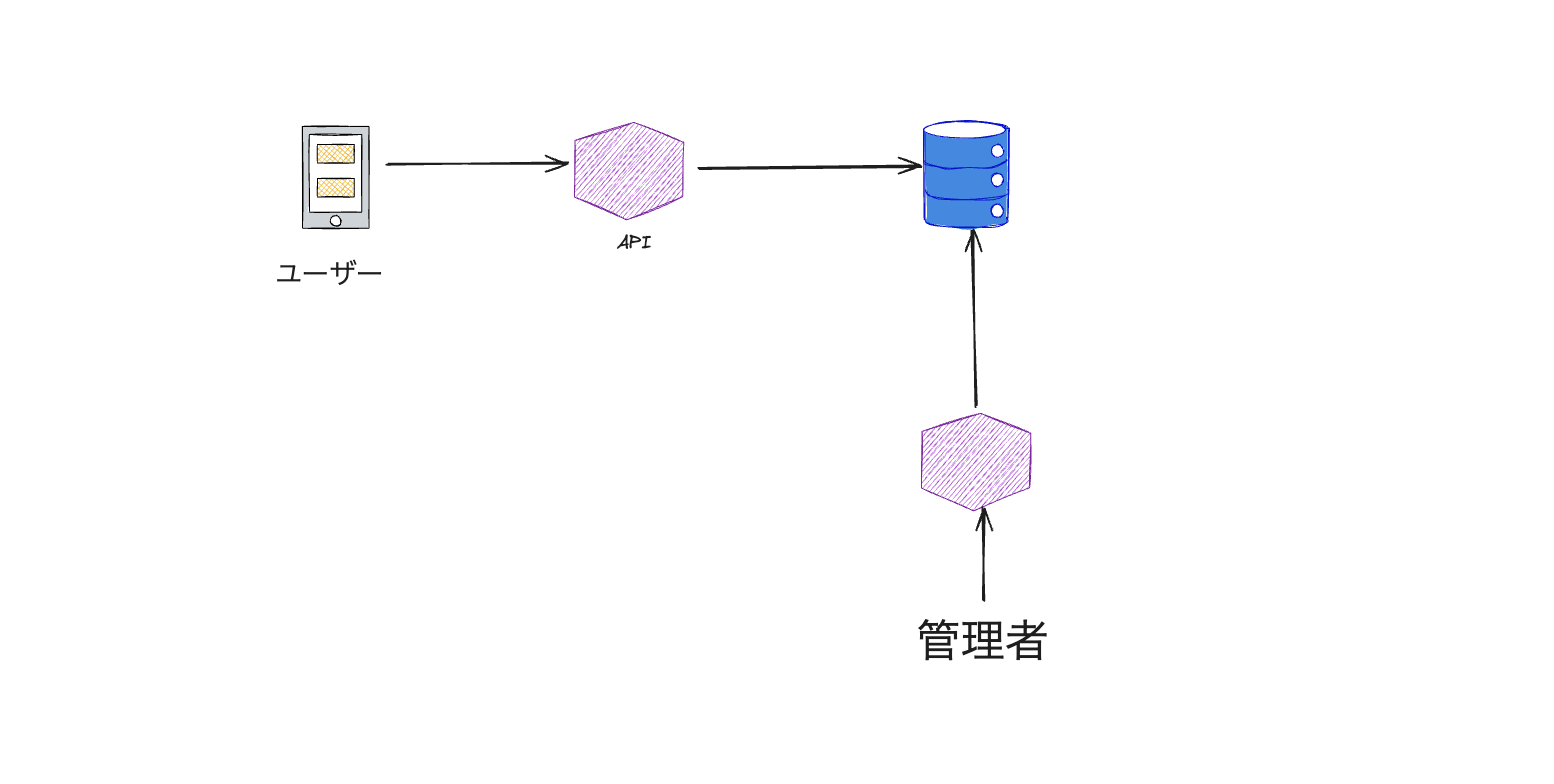
ニュース記事の作成 (管理者向け)
ユーザーは以下の属性を持つ投稿を作成できるようにします:
- コンテンツ(テキストのみにしましょう)
- カテゴリー(複数可)
- 作成時間
これらの属性は、読者のためにニュースフィードをフィルタリングし整理する上で重要です。
データベースの検討:NoSQL vs SQL
NoSQLの利点:
- スケーラビリティ:大規模なデータセットに対して容易に水平スケーリングが可能
- 柔軟性:スキーマレス設計によりデータ構造の変更が容易
- パフォーマンス:単純なクエリに対して高速な読み書きが可能
- 非構造化または半構造化データに適している
SQLの利点:
- ACID準拠:データの整合性と一貫性を保証
- 複雑なクエリ:結合や複雑なトランザクションをサポート
- 明確な関係を持つ構造化データに適している
データベースの選択:SQL このニュースフィードシステムでは、以下の理由からSQLデータベースで開始します:
- 関係の整合性:投稿はユーザーやカテゴリーとの明確な関係があり、SQLはこれをうまく扱える
- ACID準拠:投稿の作成や更新において重要な、トランザクションのアトミック性を保証
- 複雑なクエリ:ユーザー設定やカテゴリーに基づいて投稿を取得する際、効率的なフィルタリングと結合が可能
負荷計算
前提条件:
- 1日あたり10,000記事
- 24時間にわたって分散
計算:
- 1時間あたりの記事数:10,000 / 24 ≈ 417
- 1分あたりの記事数:417 / 60 ≈ 7
- 1秒あたりの記事数:7 / 60 ≈ 0.12
結論:最適化されたSQLデータベースは、新しい記事に対して1秒あたり0.12の書き込み操作を容易に処理できます。読み取り操作やユーザーとのインタラクションを考慮しても、現代のSQLデータベースは1秒あたり数千のトランザクションを処理する能力があり、これは我々の要件を十分に満たしています。
カテゴリーのフォロー/アンフォロー (ユーザー向け)
ユーザーがカテゴリーをフォローできる機能を実装します。この機能は、第一段階で選択したSQLデータベースの特性を考慮すると、自然な拡張となります。
また、カテゴリーのフォロー/アンフォロー操作は、記事の投稿や閲覧に比べて頻度が低いと予想されます。そのため、この機能による著しい負荷増加は見込まれませんのでSQLデータベースにするのは大丈夫ではないかと考えています。
SQLにcategory_userテーブルを作成
- user_id(外部キー:usersテーブル)
- category_id(外部キー:categoriesテーブル)
user_id と category_id の組み合わせにユニーク制約を設定
ニュースフィードを取得:
ユーザーがフォローしているカテゴリーの投稿を作成時間順に表示するフィード機能を実装します。
フィードの表示は以下の手順に分解できます:
- 特定のユーザーがフォローしているすべてのカテゴリーを取得する。
- それらのカテゴリーからすべての投稿を取得する。
- 投稿を時間順にソートしてユーザーに返す。
これらのステップは、1つのSQLクエリで実行できます。以下に、基本的なSQLクエリの例を示します:
SELECT ...
FROM article p
JOIN category_user ON p.category_id = category_user.category_id
WHERE category_user.user_id = :user_id
ORDER BY p.created_at DESC
LIMIT 50;
実際の面接では、以下のように説明するでしょう: 「この解決策はスケールしないことは承知していますが、まずはナイーブな解決策から始めて、その後でスケーリングの問題に個別に対処していきたいと思います。」
この設計から、以下の潜在的な問題点があります:
- ユーザーが多数のカテゴリーをフォローしている可能性がある。
- 各カテゴリーに多数の投稿がある可能性がある。
- (1)または(2)の理由により、投稿の総数が非常に多くなる可能性がある。
これに関するスケーリングの話はは次のセクションで話します。一旦ここまでは求められている機能が揃ってデータの流れもわかってきたので一旦機能要件は完成しています。
詳細なコンポーネント、最適化、およびその他の機能
ニュースフィードを取得のスケーリング
スケーリングの問題に取り組む前に、システムの制約条件を明確にすることが重要です。これにより、より現実的で実装可能な解決策を見出すことができます。またこれはコミュニケーション力などにも評価されるので意識しておくと良いです
制約条件の検討
面接官に以下のような質問をすることで、製品設計の柔軟性を探ることができます:
- フォロー数の制限: 「ユーザーがフォローできるカテゴリー数に上限を設けることは可能でしょうか?」
- フィード更新の遅延許容度: 「新しいニュースがフィードに表示されるまでの遅延をどの程度許容できますか?」
ユーザーがフィードを取得する際、多数のカテゴリーと記事に対して複雑な結合クエリが実行されます。これは特に、ユーザーが多くのカテゴリーをフォローしている場合や、システムの利用者が増加した場合、データベースに問い合わせる際に時間がかかり負荷になります。時間がかかると使えるコネクションプールが少なくなって、新しいリクエストの処理が遅延したり、最悪の場合タイムアウトエラーが発生する可能性があります。
具体的には以下のような問題が発生する可能性があります:
-
コネクションプールの枯渇: 長時間実行されるクエリがデータベースコネクションを占有し続けるため、他のリクエストが使用できるコネクションが減少します。これにより、新しいリクエストの処理が遅延したり、コネクションの取得待ちが発生したりします。
-
データベースサーバーのリソース消費: 複雑なクエリや大量のデータを扱うクエリは、データベースサーバーのCPUやメモリを大量に消費します。これにより、他のクエリの処理も遅くなり、全体的なシステムのパフォーマンスが低下します。
-
I/O負荷の増加: 大量のデータを扱うクエリは、ディスクI/Oを増加させます。特に、インデックスが適切に設定されていない場合や、大規模なテーブルスキャンが発生する場合に顕著です。これにより、ディスクI/Oがボトルネックとなり、クエリの実行時間が長くなります。
-
ネットワーク帯域幅の消費: 大量のデータを取得するクエリは、データベースサーバーからアプリケーションサーバーへの大量のデータ転送を引き起こします。これにより、ネットワーク帯域幅が消費され、他のリクエストの処理にも影響を与える可能性があります。
-
スケーラビリティの制限: データベースへの問い合わせが複雑になればなるほど、水平スケーリング(サーバーの追加)による性能向上が難しくなります。これは、複雑な結合やソート操作が必要な場合に特に顕著です。
これらの問題が重なると、システム全体の応答性が低下し、ユーザー体験が悪化する可能性があります。さらに、システムの成長に伴い、これらの問題はより顕著になり、最終的にはシステムの安定性や信頼性に影響を与える可能性があります。
この問題に対処するための選択肢としては、以下のようなものが考えられます:
読み取り専用レプリカの導入:
- 読み取り専用のデータベースレプリカを複数用意し、読み取りクエリを分散させます。
- これにより、主データベースの負荷を軽減し、全体的なパフォーマンスを向上させることができます。
ただし、レプリカの導入は問題の根本的な解決策というよりは、時間を稼ぐための良い第一歩だと考えています。レプリカを導入することで、読み取りクエリを分散させ、主データベースの負荷を軽減することができますが、データ量が増加し続ける場合、最終的にはレプリカも同じボトルネックに直面する可能性があります。
キャッシング:
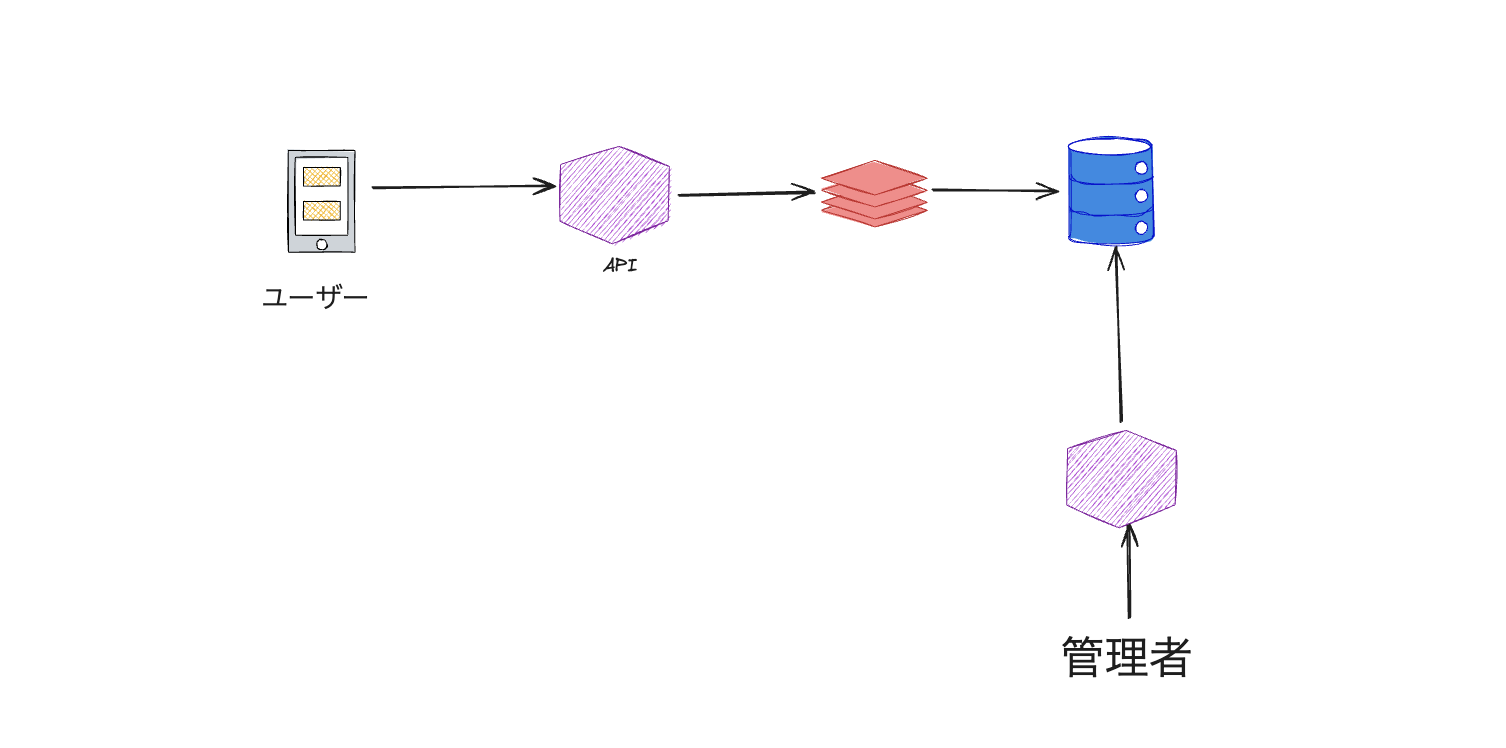
- Redisなどのインメモリキャッシュを使用して、頻繁にアクセスされるフィードをキャッシュします。
- これにより、データベースへのアクセスを減らし、応答時間を大幅に短縮できます。
キャッシングを実装する際、最も重要なのはキー/バリューの設計です。我々のクエリ結果は主にカテゴリーに依存しているため、カテゴリーの特性を明確にすることが重要です。
ここで考慮すべき重要な点は、「カテゴリーの数はどれくらいあるか?」です。
a) カテゴリーの数が少ない場合: カテゴリーをキーとしてキャッシュするのが効果的です。例えば:
cache_key = f"category:{sorted_category_ids}:latest_articles"
cached_articles = redis_client.get(cache_key)
if not cached_articles:
articles = fetch_latest_articles_for_category(category_ids)
redis_client.setex(cache_key, 300, json.dumps(articles)) # 5分時間キャッシュ
b) カテゴリーの数が多く、各ユーザーが独自のカテゴリーセット(もしくは別の条件)を持つ場合: ユーザーIDをキーとしてキャッシュするのが効果的です。例えば:
cache_key = f"user:{user_id}:feed"
cached_feed = redis_client.get(cache_key)
if not cached_feed:
feed = generate_user_feed(user_id)
redis_client.setex(cache_key, 3600, json.dumps(feed)) # 1時間キャッシュ
今のニュースサイトの場合、カテゴリーをキーとしてキャッシュするのが理にかなっています。カテゴリーベースのキャッシングの大きな利点は、ユーザーがフォローするカテゴリーを更新した場合でも、キャッシュの無効化について考える必要がないことです。ユーザーは単に別のキャッシュを使用するか、存在しない場合は新しいキャッシュを作成することになります。
現在のキャッシュ戦略では、5分間のキャッシュ有効期限を設定していますが、これはリアルタイム性を犠牲にしている可能性があります。リアルタイムのフィード更新を実現するためには、どんな戦略が考えられるか面接官とディスカションしてみても良いかもしれません。
- 機械学習を用いたパーソナライゼーション:
- cacheのhot key(特定の記事やカテゴリーがバズってる場合)
- 古い記事数の処理(cold storageなどの検討)